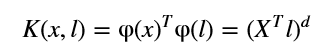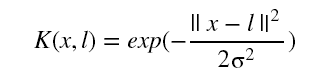Loading required package: StanHeaders
rstan (Version 2.21.7, GitRev: 2e1f913d3ca3)
For execution on a local, multicore CPU with excess RAM we recommend calling
options(mc.cores = parallel::detectCores()).
To avoid recompilation of unchanged Stan programs, we recommend calling
rstan_options(auto_write = TRUE)
Attaching package: 'rstan'
The following object is masked from 'package:tidyr':
extract
library(brms)
Loading required package: Rcpp
Loading 'brms' package (version 2.18.0). Useful instructions
can be found by typing help('brms'). A more detailed introduction
to the package is available through vignette('brms_overview').
Attaching package: 'brms'
The following object is masked from 'package:rstan':
loo
The following objects are masked from 'package:tidybayes':
dstudent_t, pstudent_t, qstudent_t, rstudent_t
The following object is masked from 'package:stats':
ar
- Online documentation and vignettes at mc-stan.org/loo
- As of v2.0.0 loo defaults to 1 core but we recommend using as many as possible. Use the 'cores' argument or set options(mc.cores = NUM_CORES) for an entire session.
Attaching package: 'loo'
The following object is masked from 'package:rstan':
loo
seed <-9547set.seed(seed)
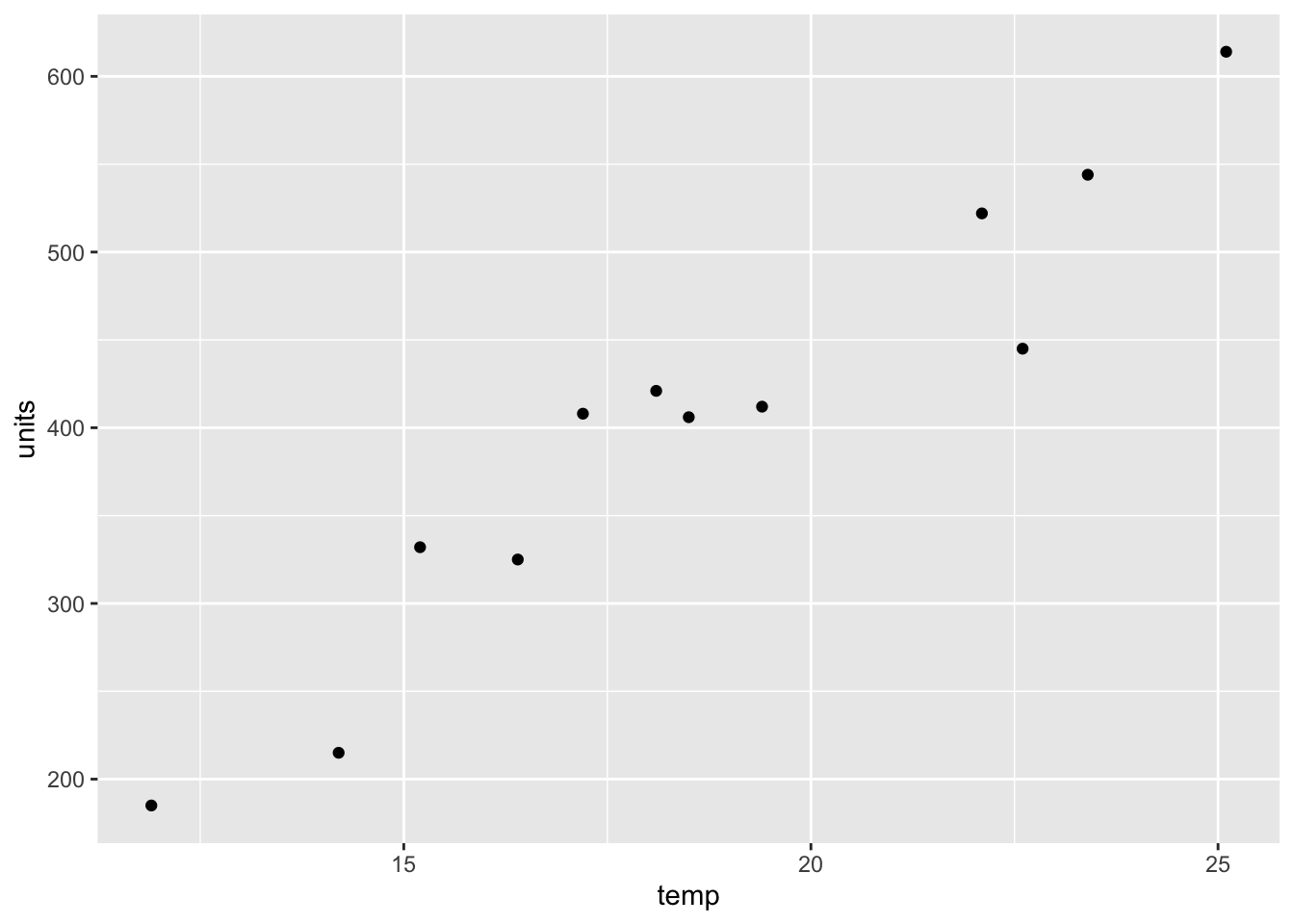
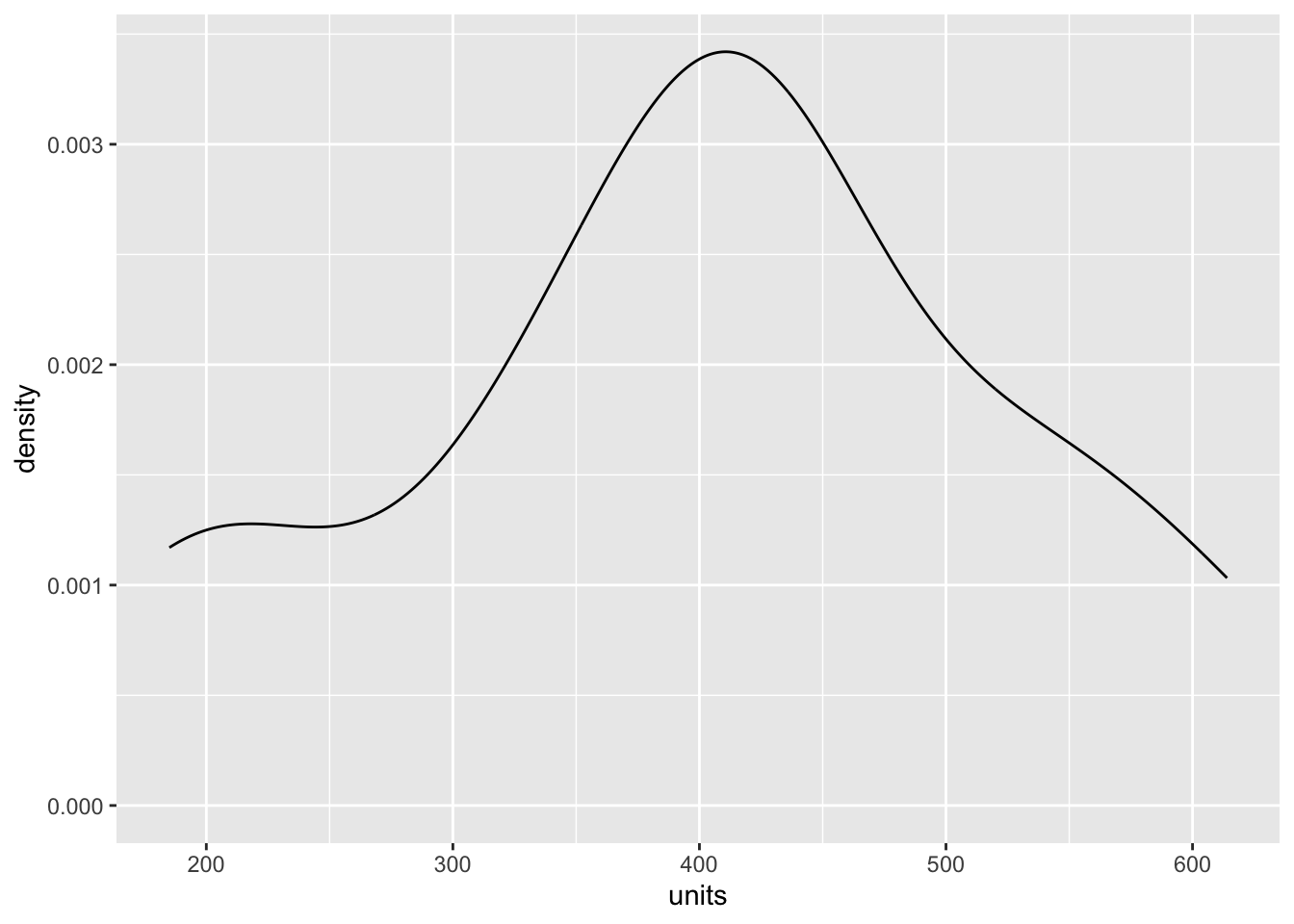
stan_data <-list(N =nrow(icecream),x = icecream$temp, y = icecream$units )fit_normal <-stan(model_code = stan_program, data = stan_data)
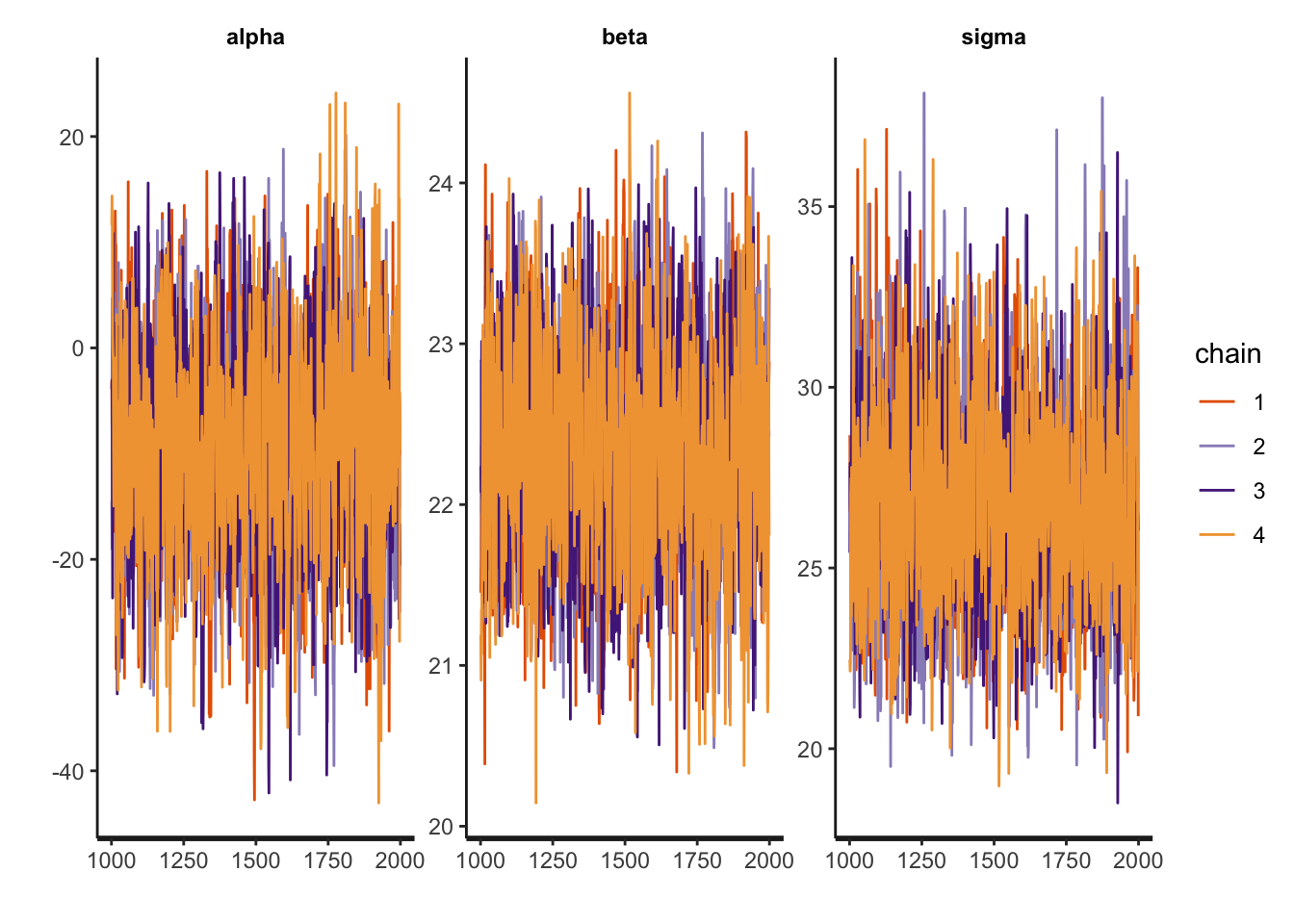
Traceplot图
traceplot(fit_normal)
img
1 主观概率与不确定性
不确定的高低用概率来表示,必然包含人们的主观判断;
核函数:https://en.wikipedia.org/wiki/Positive-definite_kernel是作为一种运算技巧(Kernel Function)若\(\phi(x)\)是\(x\)在高维的映射,那么我们定义核函数为: \[
K(x,l)=\phi(x)^T\phi(l)
\]类似的,如果特征维度为 n ,映射的阶数为 d,那我们可以得到的结果是: