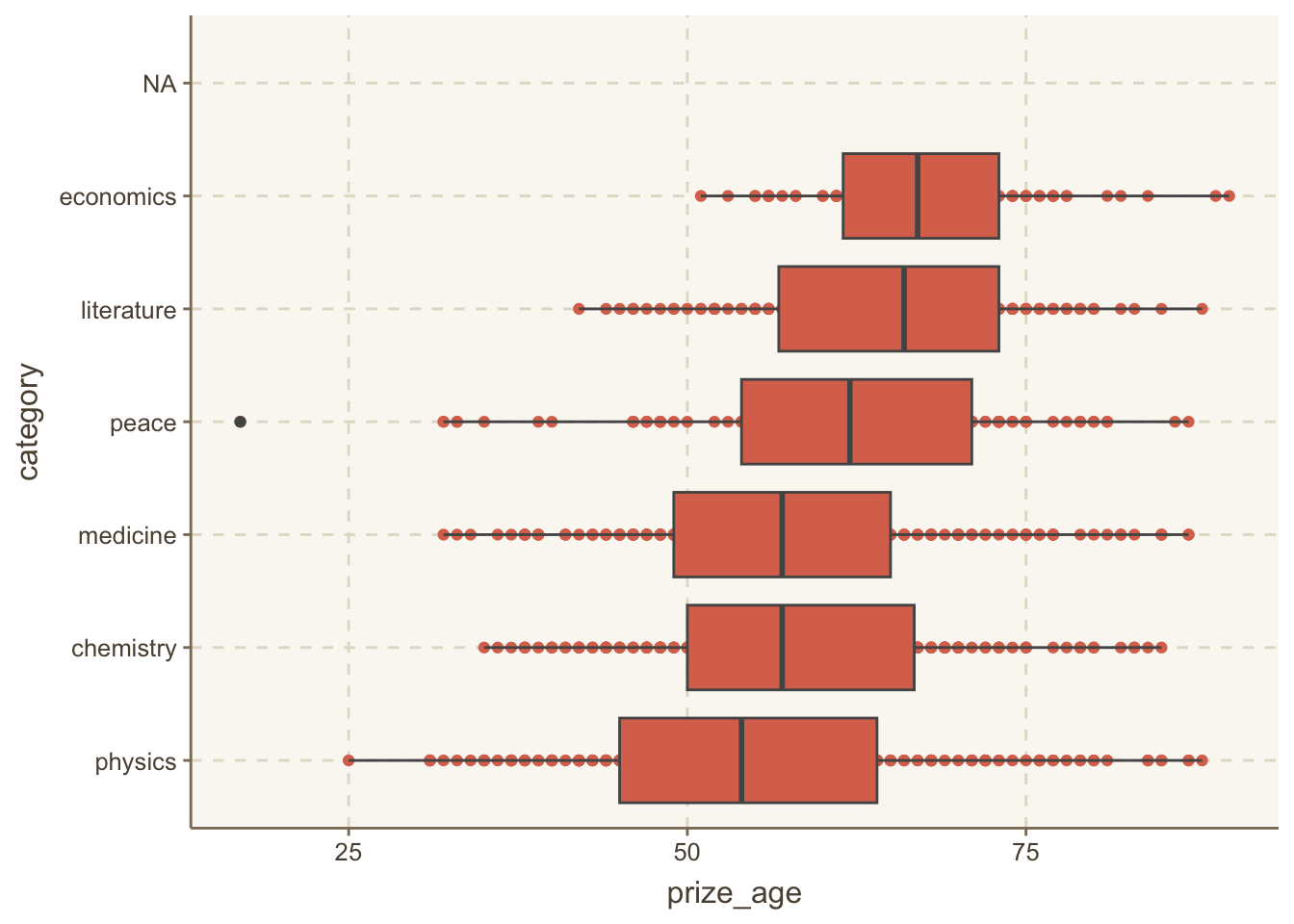
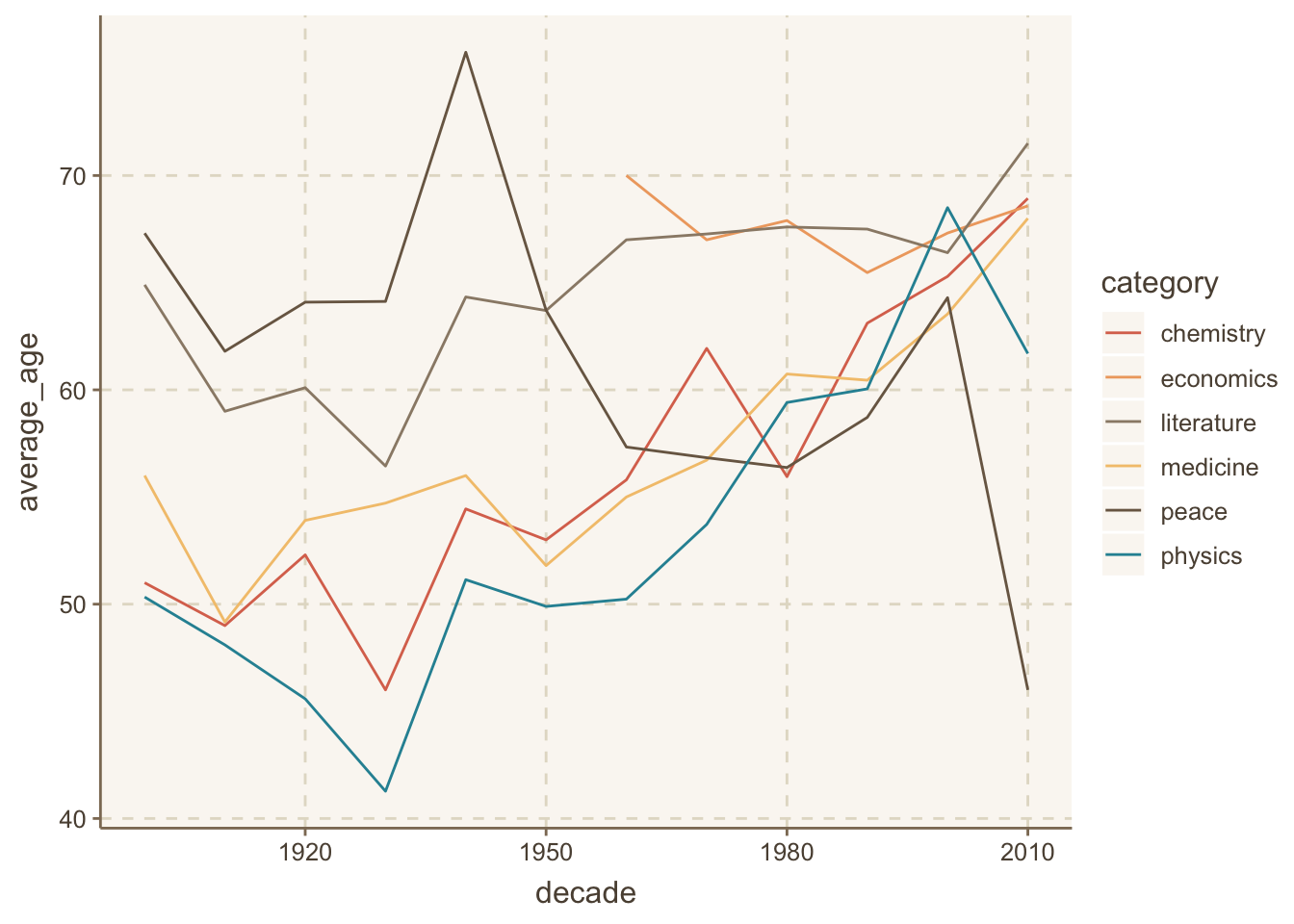
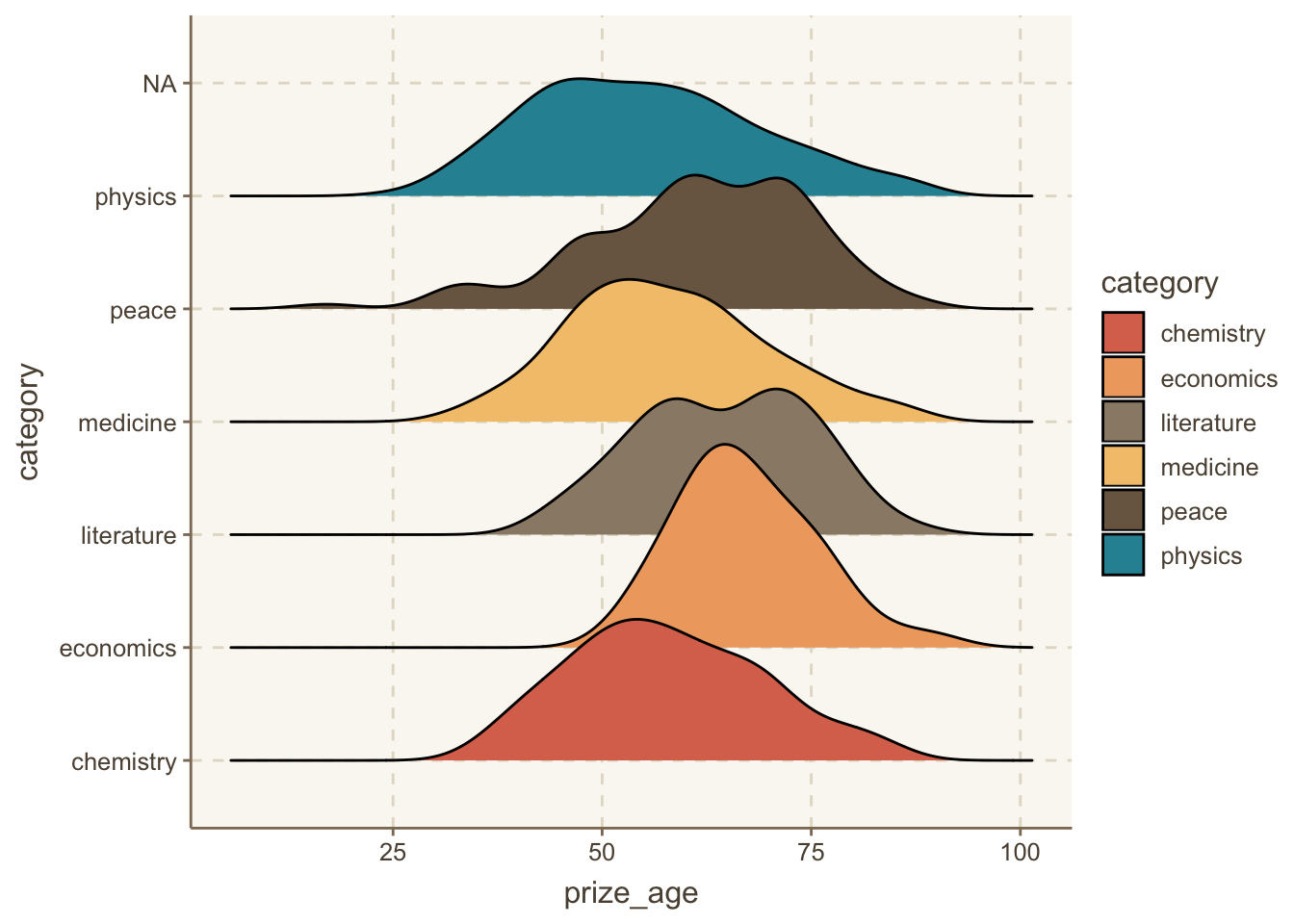
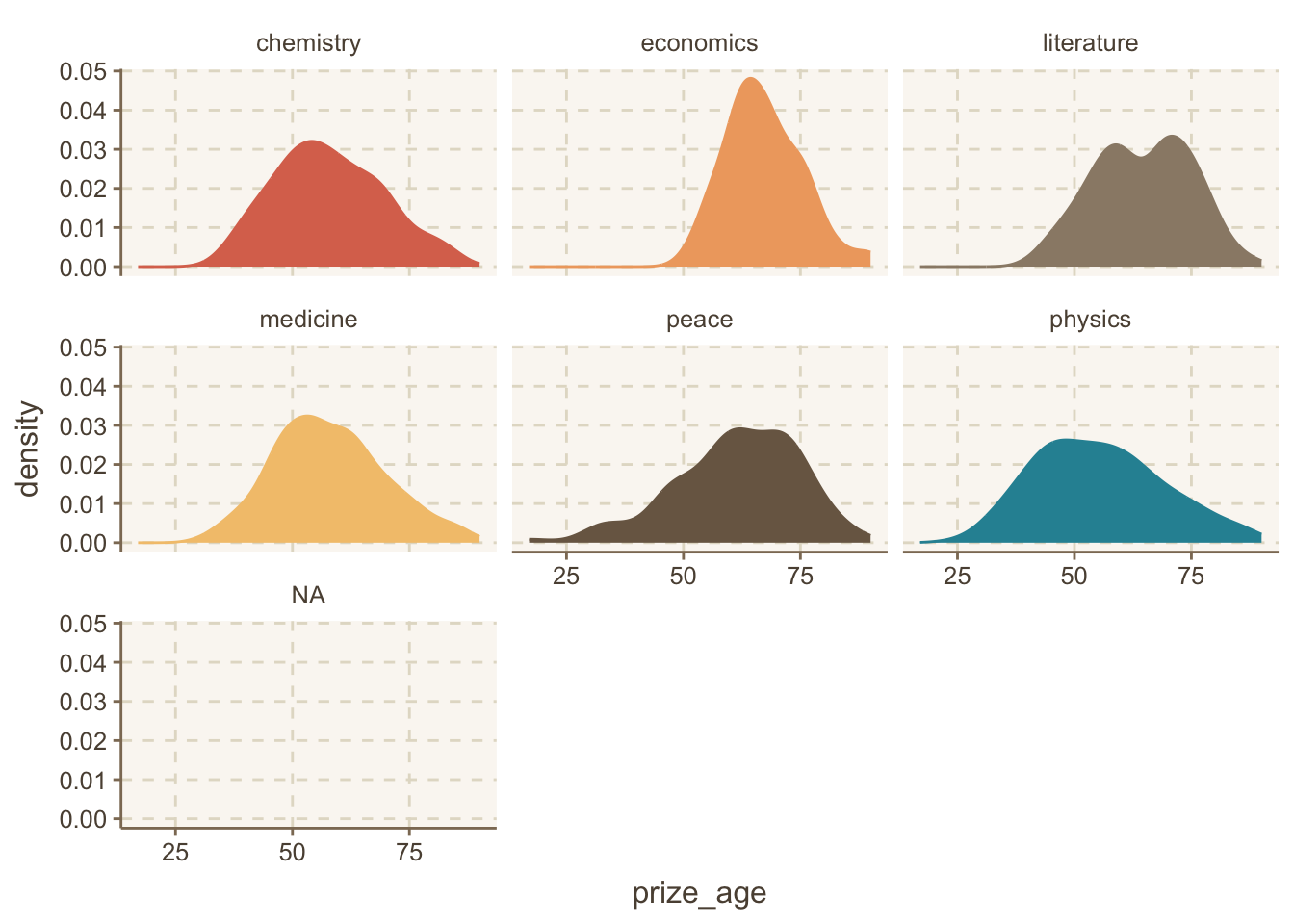
Loading required package: timechange
Attaching package: 'lubridate'
The following objects are masked from 'package:base':
date, intersect, setdiff, union
df<-read_csv('nobel_prize_by_winner.csv')
Rows: 972 Columns: 20
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (17): firstname, surname, born, died, bornCountry, bornCountryCode, born...
dbl (3): id, year, share
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
df
# A tibble: 972 × 20
id firstname surname born died bornC…¹ bornC…² bornC…³ diedC…⁴ diedC…⁵
<dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 846 Elinor Ostrom 8/7/… 6/12… USA US "Los A… USA US
2 846 Elinor Ostrom 8/7/… 6/12… USA US "Los A… USA US
3 783 Wangari Mu… Maathai 4/1/… 9/25… Kenya KE "Nyeri" Kenya KE
4 230 Dorothy Cr… Hodgkin 5/12… 7/29… Egypt EG "Cairo" United… GB
5 918 Youyou Tu 12/3… 0000… China CN "Zheji… <NA> <NA>
6 428 Barbara McClin… 6/16… 9/2/… USA US "Hartf… USA US
7 773 Shirin Ebadi 6/21… 0000… Iran IR "Hamad… <NA> <NA>
8 597 Grazia Deledda 09/2… 8/15… Italy IT "Nuoro… Italy IT
9 615 Gabriela Mistral 04/0… 1/10… Chile CL "Vicu_… USA US
10 782 Elfriede Jelinek 10/2… 0000… Austria AT "M\xf4… <NA> <NA>
# … with 962 more rows, 10 more variables: diedCity <chr>, gender <chr>,
# year <dbl>, category <chr>, overallMotivation <chr>, share <dbl>,
# motivation <chr>, name <chr>, city <chr>, country <chr>, and abbreviated
# variable names ¹bornCountry, ²bornCountryCode, ³bornCity, ⁴diedCountry,
# ⁵diedCountryCode
# A tibble: 29 × 2
country n
<chr> <int>
1 USA 339
2 United Kingdom 89
3 Germany 43
4 France 34
5 Federal Republic of Germany 23
6 Switzerland 21
7 Sweden 17
8 Japan 16
9 the Netherlands 11
10 Denmark 9
# … with 19 more rows
8.3.2 获奖类别
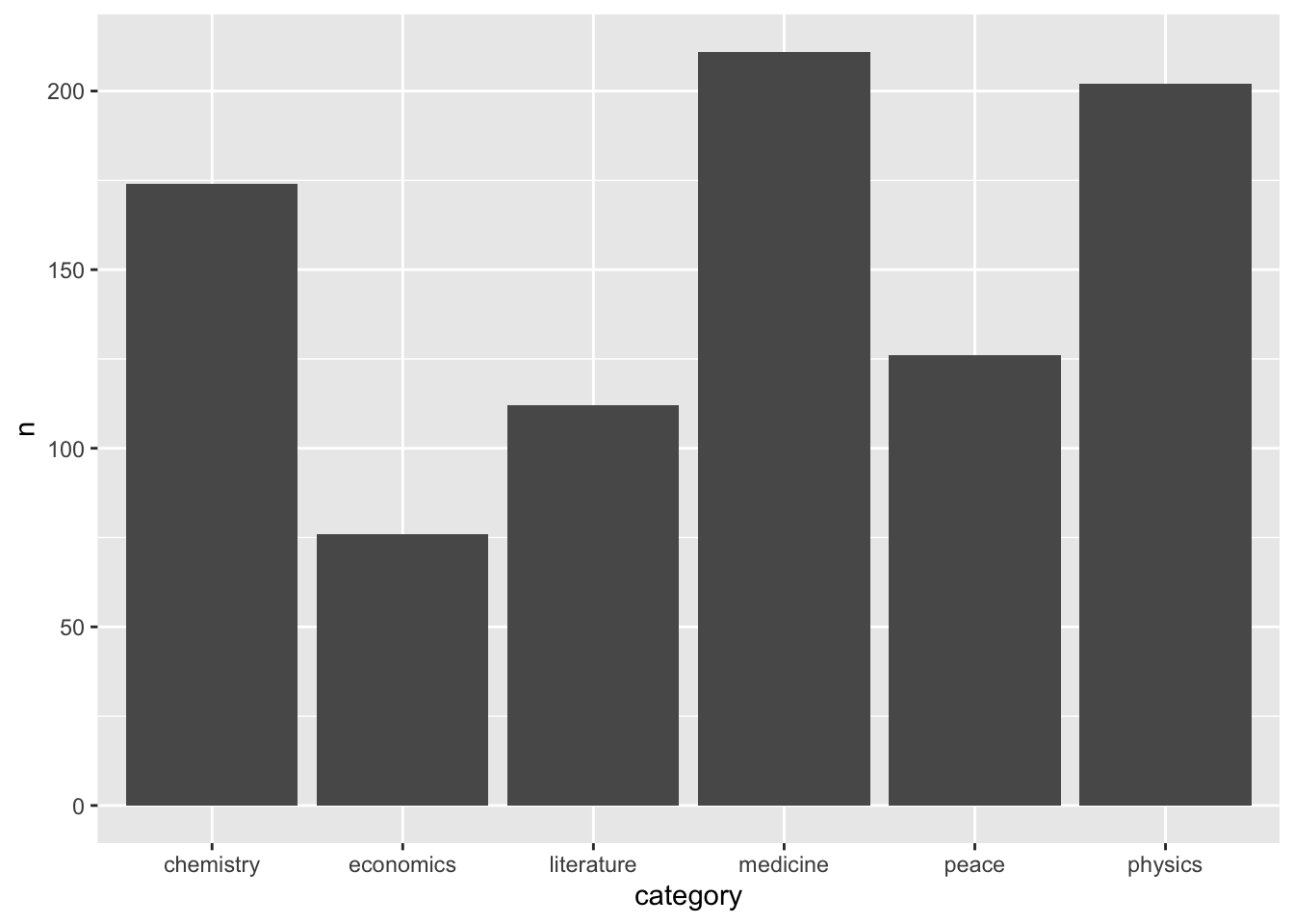
df %>%count(category)
# A tibble: 7 × 2
category n
<chr> <int>
1 chemistry 174
2 economics 76
3 literature 112
4 medicine 211
5 peace 126
6 physics 202
7 <NA> 6
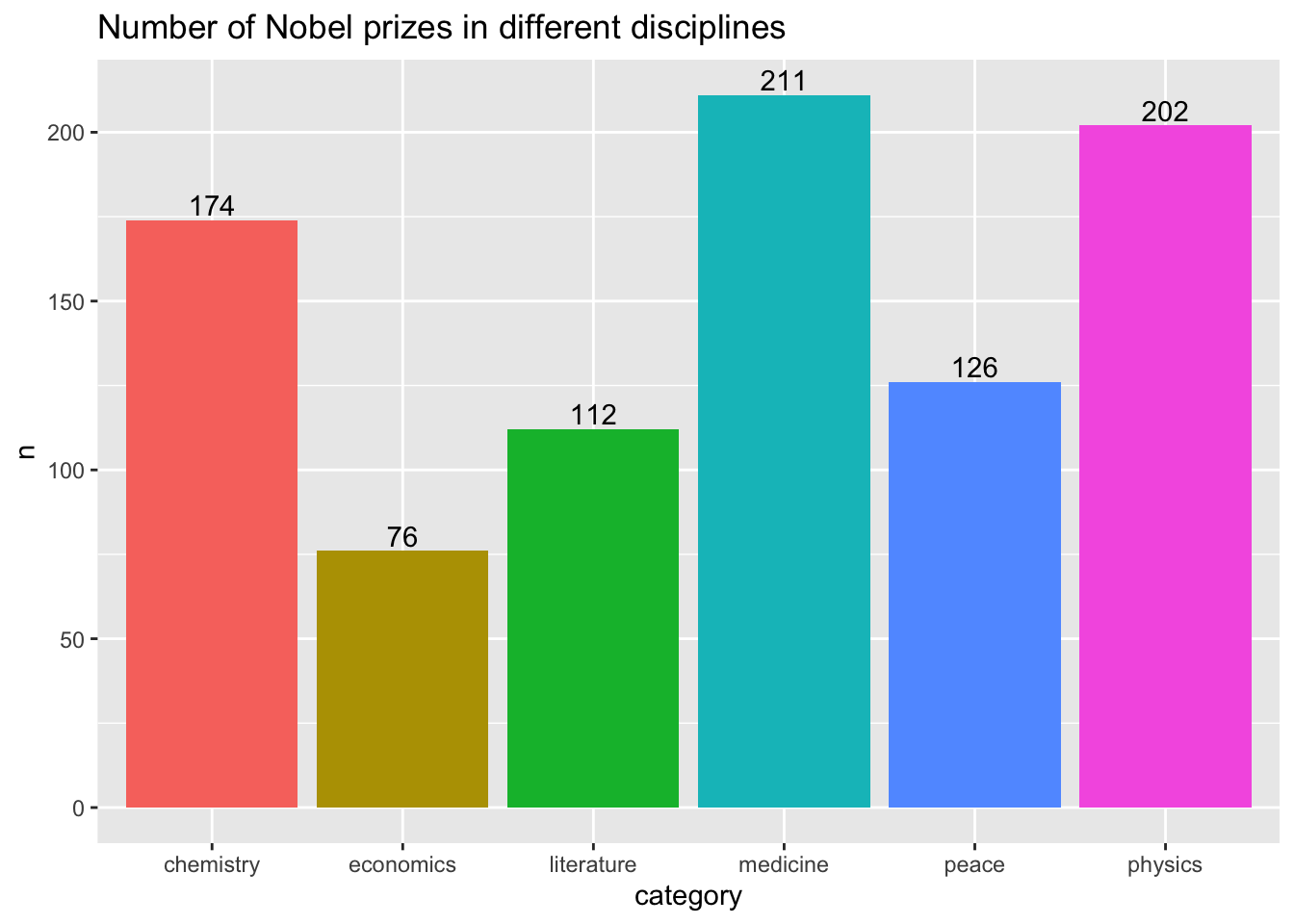
df %>%drop_na(category)%>%count(category)%>%ggplot(aes(x = category,y = n,fill = category))+geom_col()+geom_text(aes(label=n),vjust=-0.25)+labs(title ="Number of Nobel prizes in different disciplines") +theme(legend.position ="none")
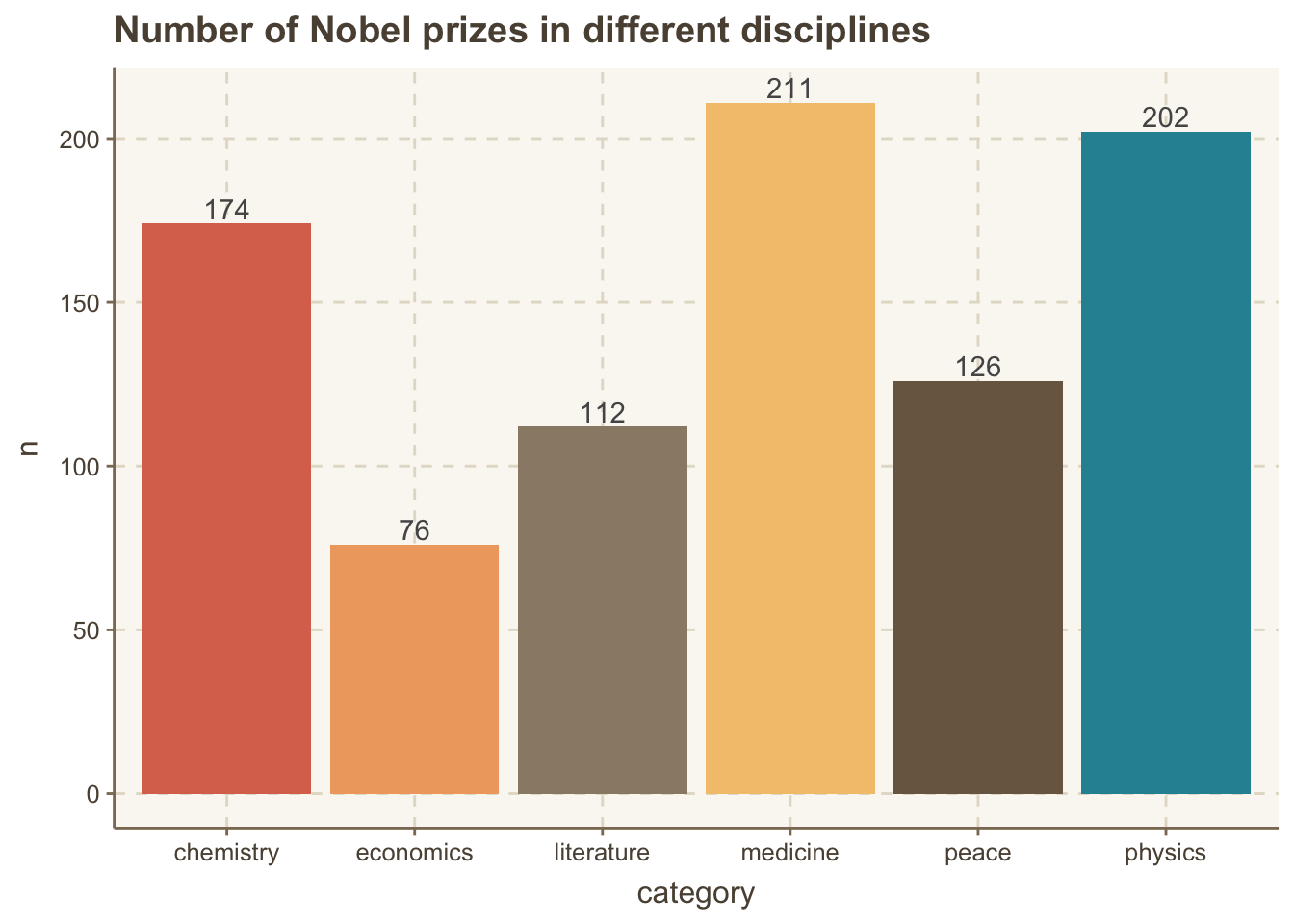
library(ggthemr)ggthemr("dust")df %>%drop_na(category)%>%count(category)%>%ggplot(aes(x = category,y = n,fill = category))+geom_col()+geom_text(aes(label=n),vjust=-0.25)+labs(title ="Number of Nobel prizes in different disciplines") +theme(legend.position ="none")
# A tibble: 11 × 4
firstname surname year category
<chr> <chr> <dbl> <chr>
1 Youyou Tu 2015 medicine
2 Gao Xingjian 2000 literature
3 Charles Kuen Kao 2009 physics
4 Liu Xiaobo 2010 peace
5 Ei-ichi Negishi 2010 chemistry
6 Edmond H. Fischer 1992 medicine
7 Daniel C. Tsui 1998 physics
8 Tsung-Dao (T.D.) Lee 1957 physics
9 Chen Ning Yang 1957 physics
10 Walter Houser Brattain 1956 physics
11 Mo Yan 2012 literature
# A tibble: 6 × 24
id firstname surname born died bornC…¹ bornC…² bornC…³ diedC…⁴ diedC…⁵
<dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 846 Elinor Ostrom 8/7/… 6/12… USA US Los An… USA US
2 783 Wangari Muta Maathai 4/1/… 9/25… Kenya KE Nyeri Kenya KE
3 230 Dorothy Cro… Hodgkin 5/12… 7/29… Egypt EG Cairo United… GB
4 918 Youyou Tu 12/3… 0000… China CN Zhejia… <NA> <NA>
5 428 Barbara McClin… 6/16… 9/2/… USA US Hartfo… USA US
6 773 Shirin Ebadi 6/21… 0000… Iran IR Hamadan <NA> <NA>
# … with 14 more variables: diedCity <chr>, gender <chr>, year <dbl>,
# category <chr>, overallMotivation <chr>, share <dbl>, motivation <chr>,
# name <chr>, city <chr>, country <chr>, birthyear <dbl>, decade <dbl>,
# prize_age <dbl>, full_name <chr>, and abbreviated variable names
# ¹bornCountry, ²bornCountryCode, ³bornCity, ⁴diedCountry, ⁵diedCountryCode
# A tibble: 6 × 24
id firstname surname born died bornC…¹ bornC…² bornC…³ diedC…⁴ diedC…⁵
<dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 846 Elinor Ostrom 8/7/… 6/12… USA US Los An… USA US
2 783 Wangari Muta Maathai 4/1/… 9/25… Kenya KE Nyeri Kenya KE
3 230 Dorothy Cro… Hodgkin 5/12… 7/29… Egypt EG Cairo United… GB
4 918 Youyou Tu 12/3… 0000… China CN Zhejia… <NA> <NA>
5 428 Barbara McClin… 6/16… 9/2/… USA US Hartfo… USA US
6 773 Shirin Ebadi 6/21… 0000… Iran IR Hamadan <NA> <NA>
# … with 14 more variables: diedCity <chr>, gender <chr>, year <dbl>,
# category <chr>, overallMotivation <chr>, share <dbl>, motivation <chr>,
# name <chr>, city <chr>, country <chr>, birthyear <dbl>, decade <dbl>,
# prize_age <dbl>, full_name <chr>, and abbreviated variable names
# ¹bornCountry, ²bornCountryCode, ³bornCity, ⁴diedCountry, ⁵diedCountryCode